Delta-1.0: Redefining the Economics of Embodied Intelligence with Causal Reasoning
The First Principle of Embodied Intelligence
In the grand narrative of artificial intelligence expanding into the physical world, we must return to the field's most fundamental philosophical question. Traditional theories of embodied cognition—from Heidegger's concept of "being-in-the-world" to Merleau-Ponty's "phenomenology of perception"—highlight a profound insight: intelligence and the physical body are inseparable. Intelligence must arise and exist through continuous interaction with the environment.
Yet this existential perspective mainly addresses what intelligence is, while leaving open a deeper question: how it can persist. Once intelligence takes on a physical embodiment, it is no longer a Platonic abstraction of symbols but a "mortal" system subject to the ultimate constraints of physical laws. From the entropy increase described by the second law of thermodynamics to the energetic constraints that shape biological evolution, the persistence of all forms of existence in the universe follows a hidden but universal economic principle.
If embodied intelligence is to move beyond the idealized world of simulation and achieve true autonomy in an uncertain, resource-constrained physical world, its entire perception–cognition–action loop must be governed by a higher-order principle. This principle is simple: maximize survival and task performance while minimizing resource consumption. This is not merely a technical design choice—it is the fundamental measure of an intelligent agent's "right to exist" in the physical world.
The Data Bottleneck in Embodied Intelligence
However, when we examine the current state of embodied intelligence through this principle, a deep paradox emerges. Despite significant progress in algorithm design and model scale, the field remains constrained by a more fundamental limitation: the extreme scarcity of data. Unlike the internet era, where digital information can be copied and transmitted at near-zero cost, the data required for embodied intelligence is physical information, which can only be obtained through costly interaction with the real world.
Consider the example of Google DeepMind. In building the pioneering RT-2 model, collecting 130,000 data points across more than 700 tasks required 13 robots to operate continuously in an office kitchen environment for 17 months, along with substantial costs in hardware depreciation, energy consumption, and human supervision. Such persistently high data acquisition costs fundamentally violate the very principle of efficiency that intelligent agents themselves are meant to embody. As a result, the process through which we train intelligent agents becomes highly resource-intensive rather than efficient. In effect, we are attempting to build systems that pursue efficiency through an inherently inefficient process.
This contradiction lies at the heart of the current development trajectory of embodied intelligence. Without addressing the cost of data acquisition, expecting intelligence to emerge at scale is like asking a species to evolve in an environment where its energy expenditure exceeds its intake—progress will inevitably be slow and constrained.
The Delta-1.0 Architecture
Faced with this contradiction, we believe that any attempt to bypass the principle of efficiency will ultimately fail. The real path forward is not unlimited resource investment, but a return to first principles and a fundamental restructuring of the economics of data generation. Guided by a quantitative mindset deeply embedded in our team—namely, an obsessive focus on input–output efficiency—we believe the data problem must be addressed from two directions: reducing the marginal cost of acquiring data on the input side, and improving the efficiency with which that data is utilized during learning and inference.
Based on this insight, we developed a new embodied intelligence architecture called Delta-1.0. This architecture aims to break the expensive barrier between human demonstrations and machine training, creating a self-driven, co-evolving data loop. At its core are two major components: a foundation model that serves as the system’s central decision-making model by unifying the semantic spaces of vision, language, and action, enabling it to understand and execute complex tasks; and the PRISM (Policy and Reward learning with Imagined State Models) module, which functions as the evolutionary engine of the system.
PRISM incorporates an ability to imagine and reason about the environment. At the heart of this capability is a world model—an internal simulation that learns to predict how the environment will change in response to different actions. Instead of relying solely on trial and error in the real world, the agent first uses this world model to imagine possible action sequences and anticipate their outcomes. By filtering out ineffective strategies in simulation, it can focus its real-world interactions on the most promising paths. This “imagine before acting” approach allows task specialists to acquire new skills with far fewer real-world interactions, significantly improving data efficiency and task success rate.
PRISM: Self-Generating Data through Causal Reasoning and Imagination
The design philosophy of PRISM begins by addressing the cost problem at the data acquisition stage. Instead of passively waiting for human demonstrations, the system actively generates experience on its own. Specifically, PRISM learns highly specialized expert policies from a small set of human demonstrations. Before acting in the real environment, these experts first leverage a world model to simulate possible actions and outcomes. This “think before acting” mechanism allows them to explore autonomously and more efficiently, generating large volumes of high-quality data that contain a deep understanding of the tasks. In this way, the supply of data is expanded at its source.
However, maximizing efficiency also requires improving how the system learns from that data. We believe causal reasoning provides a fundamentally more efficient path than pure imitation learning. Human civilization has advanced not by exhaustively copying natural phenomena, but by uncovering the causal laws that govern them. From Newton’s discovery of universal gravitation to Einstein’s theory of relativity, each major intellectual leap has come from tracing observed effects back to their underlying causes.
In PRISM, we deepen this idea further. Using inverse reinforcement learning, the system infers the hidden reward functions that drive successful behavior. At the same time, it introduces an internal imagination and reasoning mechanism that allows the agent to simulate the outcomes of different strategies before acting. This transforms causal reasoning from a purely theoretical understanding of “why it works” into a practical guide for efficient action—enabling the agent to identify the core principles of task success with far fewer real‑world trials.
By combining the broad generalization capabilities of the foundation model with the deep specialization and self‑evolving data generation of PRISM, Delta-1.0 turns expensive human demonstrations into a catalyst rather than a dependency. PRISM expands the scale of available data, while the combination of causal reasoning and imagination increases the utilization efficiency and intrinsic value of each data point. Together, they form a highly efficient data flywheel that drives continual improvement and opens a sustainable, scalable path toward general embodied intelligence.
PRIME: Policy & Reward Iterative Meta-Enhancement
Within the Delta-1.0 architecture, the RISE module powers this data flywheel through an iterative meta-enhancement mechanism we developed called PRIME (Policy & Reward Iterative Meta-Enhancement). The essence of PRIME is not merely to refine existing policy experts, but to operationalize causal reasoning through two concrete and measurable learning transitions.
The first transition is a shift from reproducing surface behavior to understanding its underlying causes. Traditional behavior cloning stops at imitating the observable outcomes of human actions. PRIME, by contrast, uses bi‑level optimization to trace those outcomes back to their causes. In the inner loop, the policy network is optimized to maximize rewards predicted by a shared reward network. In the outer loop, the shared reward network—trained across tasks—is updated so that expert behaviors receive higher expected returns. Through this process, the system learns to infer the hidden reward functions that explain why certain actions lead to success. What makes this transition particularly efficient is the imagination capability built into PRISM: instead of repeatedly trying out different strategies in the real world, the agent can simulate their outcomes internally, identifying the true causal structure of the task with far less cost.
The second transition moves from isolated causal insights to shared causal understanding across tasks. The meta-enhancement mechanism in PRIME trains a shared reward network that captures causal patterns discovered in previous tasks and encodes them as transferable knowledge. When the system encounters a new task, it no longer begins from scratch. Instead, it can leverage this shared network to generate strong initial causal hypotheses. As a result, causal learning becomes less fragmented and task-specific, evolving instead into a growing network of interconnected knowledge.
These two capabilities—understanding causal structure within tasks and discovering causal relationships across tasks—allow Delta-1.0 not only to address the data cost problem, but also to provide agents with a form of insight that more closely resembles human learning. In our view, this kind of insight is far more valuable on the path toward general embodied intelligence than simply scaling compute or accumulating larger datasets.
Empirical Validation
The depth of a theory must ultimately be tested by the height of its practice. To empirically evaluate the effectiveness of the Delta-1.0 architecture in addressing the data bottleneck and improving model generalization, we designed a series of rigorous comparative experiments. We selected the representative π-0.5 model as the baseline and systematically evaluated Delta-1.0 across five different operational task dimensions.
Each experiment focuses on a specific aspect of real-world robotic generalization:
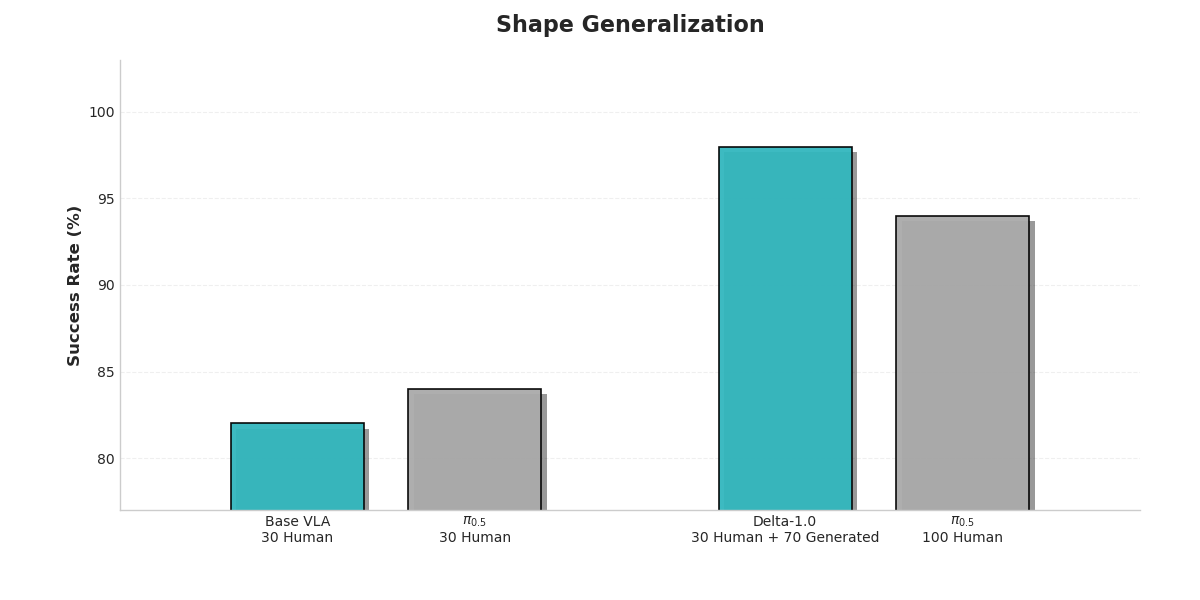
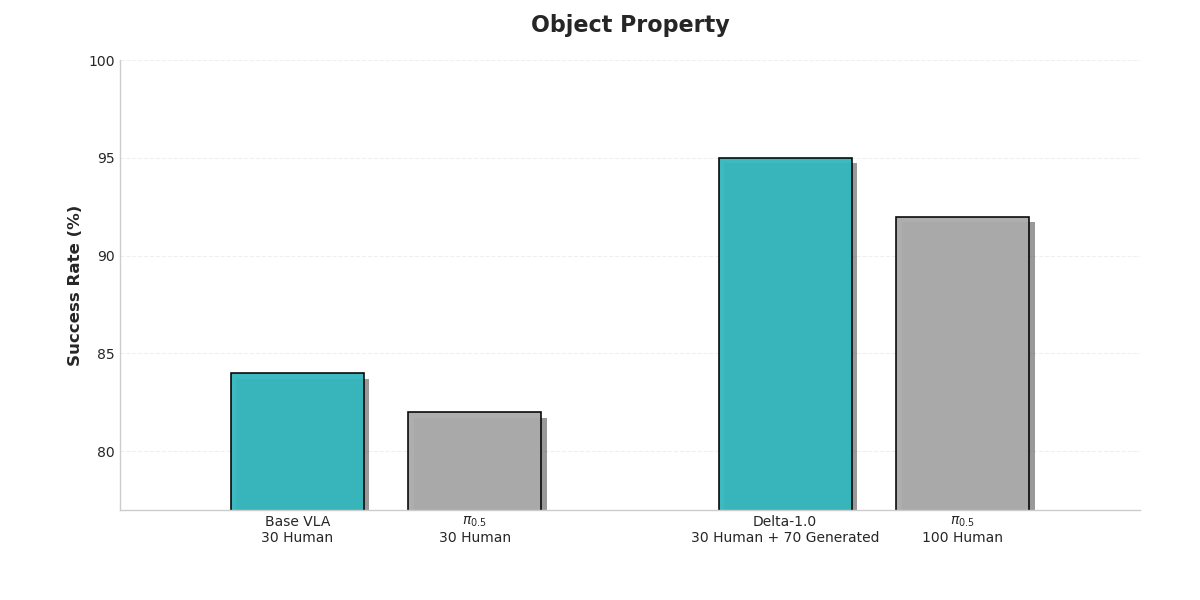
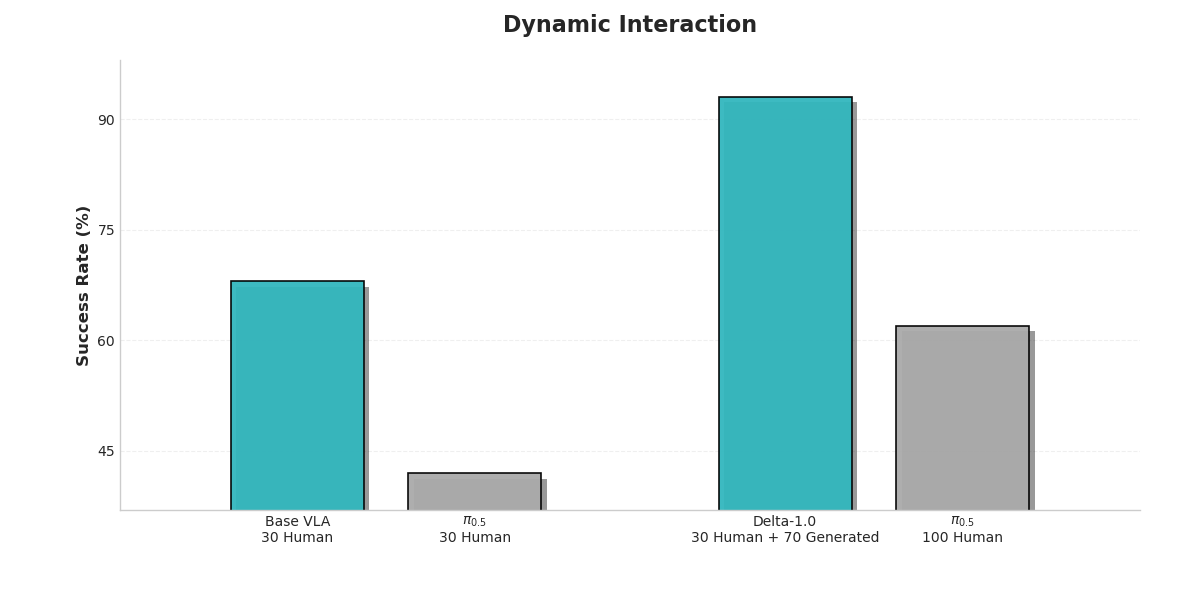
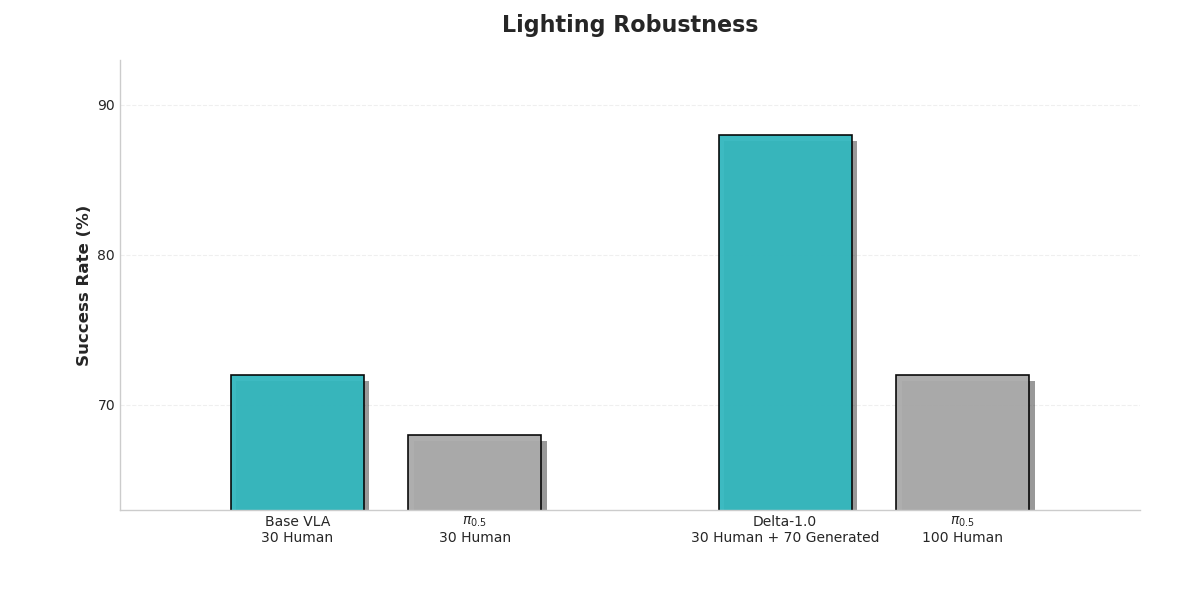
The experiments focused on two scenarios that most clearly reflect the principle of economy. The first examined generalization performance under an extreme low-data regime, where only 30 human demonstrations were available. The second compared model performance when trained with the same amount of data (100 samples), contrasting policy expert generated data produced by our system with purely human collected data.
The results clearly show that Delta-1.0 significantly outperforms the baseline across all evaluated dimensions, providing strong evidence for the effectiveness of our technical approach.
This key comparison confirms that 100 samples generated by Delta-1.0 itself produce significantly better training outcomes than the same number of purely human-collected samples. This decisively demonstrates that machine-generated data not only reduces cost but can also achieve higher data quality, because it embeds dense knowledge derived from the system’s understanding of the task’s underlying structure.
Real-World Deployment in Industrial Environments
We successfully deployed the Delta-1.0 model—originally trained on a laboratory robotic arm—onto a wheeled robot operating in an automotive manufacturing factory, enabling dynamic collaboration with assembly-line workers. This deployment served as a real-world test of the causal reasoning paradigm we advocate.

In the factory environment shown in the image, when a worker gives the natural language instruction "Help me get a hose," the robot completes the entire task pipeline end-to-end: understanding the spoken command, identifying the target object (the fire extinguisher hose), planning a path, performing a dexterous grasp, and safely delivering the item. The robot's task success rate, stability, and adaptability to the environment all exceeded expectations.
When faced with entirely new tasks such as delivering a hose—tasks that never appeared in the original training data—the system required only a small amount of real-world interaction data to adapt quickly using Delta-1.0’s data generation capabilities. The key reason is that the PRIME mechanism can efficiently infer the causal structure of a new task from very few examples, fundamentally breaking through the traditional bottleneck of data acquisition.
From highly generalized manipulation in the laboratory to autonomous operation in a factory environment, the successful deployment of Delta-1.0 demonstrates not only technical capability but also the practical realization of the efficiency principle we advocate. It shows that a technical approach grounded in causal reasoning can unlock real value in the physical world.
Toward Collective Causal Intelligence
In summary, our exploration begins with a philosophical reflection on the first principle of embodied intelligence: the persistence of any physical system must follow the universe’s fundamental law of efficiency. Using this principle as our guide, we analyzed the data bottleneck that currently constrains the field. To address this challenge, we proposed the Delta-1.0 architecture, which integrates a foundation model with PRISM through the PRIME iterative meta‑enhancement framework, introducing a new paradigm of data generation that blends causal reasoning with internal imagination.
Across evaluations in simulated environments and deployments in real industrial scenarios, Delta-1.0 demonstrates significant improvements in key dimensions such as data efficiency, generalization ability, task success rate, and deployment cost.
The significance of Delta-1.0 lies not only in delivering a higher‑performing model, but in validating a broader technological direction: intelligence can emerge through autonomous evolution grounded in causal reasoning and internal simulation, rather than relying solely on massive and expensive human imitation. PRIME’s bi‑level optimization, enriched by the ability to imagine outcomes, illustrates that enabling agents to understand why something works—the underlying cause—is far closer to the essence of intelligence than merely reproducing what was done. In this sense, an intelligent agent’s “right to exist” in the physical world can be earned by improving the efficiency of its internal understanding.
Looking ahead, we believe the next major breakthrough in embodied intelligence will come from moving beyond individual causal insight toward collective sharing of causal knowledge. Future models in the Delta series will aim to build a unified framework in which agents deployed around the world, performing different tasks, can efficiently exchange and integrate the causal rules, meta‑knowledge, and simulation‑driven insights they extract through PRISM and PRIME.
This would go far beyond simple sharing of experience data. Instead, it would enable the transmission of higher‑level knowledge about how to learn and how to anticipate.
Such a transition resembles the shift from biological evolution in individual organisms to the collective accumulation of knowledge in human civilization. When countless independent agents—each striving to minimize its own entropy increase—connect into a global network capable of sharing the “spark of wisdom,” a new order of intelligence may emerge.
We believe this represents the most economically sustainable path toward general embodied intelligence—and one that aligns most closely with the fundamental laws of the universe.